
Learn how this founder leveraged her TikTok account for revenue and audience growth while still having time to focus on other aspects of her business.
If you use Buffer, you might have experienced us having more downtime than usual recently. We want to start with an apology for not sharing more transparently along the way what’s been happening. We’ve been caught up in the work and haven’t invested enough in communicating with our community, and we’re so sorry about this misstep. We know some of our customers have had a frustrating time using Buffer recently and we need to do better by you.
This past August and September were the months we’ve experienced the most monthly incidents out of the past three years. We’re entering October in a much more stable state, but we’ve still got a lot of work planned to make our improvements long-term.
For reference, here is Buffer’s Status page where you can follow along with incidents and their resolution.
These issues have been, in large part, due to some of our work to modernize Buffer. We’ve been building Buffer since late 2010 and over the years we’ve accrued some technical debt. As much as we’ve been working to pay off debt in other areas of the company — we shared more about modernizing our salary system last year — we’ve been working hard to do the same on our Engineering team.
Though most of the incidents have come from us internally, we’ve also had several external incidents over the last few months from our partners having outages. Regardless of where the incident stemmed from, it added volume to our customer support inbox, led to unreliability in Buffer, and is far from the experience we want any Buffer user having.
Our own work to modernize Buffer causing issues for our customers has been particularly challenging for us. We pride ourselves on building a product that helps our customers build their business and delivering a world-class customer experience.
In the second quarter of this year, our Customer Advocacy team responded to 60 percent of our customers for the first time within two hours and 91 percent of our customers rated our customer support great. To put that in perspective, average customer response times are over seven hours. Though we are still above average, we’ve been struggling with not hitting our own bar for reliability and response times, and we want to use this post to share more about both of those.
With that, here’s what has been going on behind the scenes and what we’re doing to improve everyone’s experience.
The current state of Buffer, performance, and customer support
As of the writing of this blog post, our team has done a ton of work to establish what has led to downtime and slowness and we’ve been feverishly working on a more stable product.
In terms of performance, we have decreased the number of incidents in September compared to August, but we still need to improve our product’s performance.
The current state of our Customer Advocacy team
On the customer support side, we have worked hard improved our customer response time. In August, 46 percent of customers received a first response within two hours, by September, it was 59 percent. Through out this period 99 percent of our customers get a reply within 24 hours.
Due to an increase in number of customer support requests in August and added complexity due to the issues and incidents, we started September with a backlog of support requests and decided to move our Customer Advocacy team into “All Hands on Deck” for seven days. This status means that everyone dropped work outside of the inbox and moved to a five-day work week (from our usual four-day work week). With this change, we were able to get caught up on volume and significantly improve the overall customer support experience within two days.
A look at the technical side from our Engineering team
Our Engineering team has been working to implement both immediate fixes and long-term solutions. To get into the weeds a little, here’s what the Engineering team has done and what they are actively working on to continue pursuing these performance improvements:
- We've rebalanced how we handle requests to our Core API based on traffic patterns.
This has significantly improved overall latency and reduced system bottlenecks. We have already seen positive results from this change in our performance metrics.
- We've identified and are implementing fixes to make sure our database queries remain always efficient.
This includes working around a bug that was causing some queries to run much slower than expected. We're rolling this out carefully and tracking its impact to ensure it delivers the expected improvements.
- We've been addressing issues that were causing parts of our system to become less responsive under certain conditions.
We've already fixed several instances of this issue and are continuing to identify and address others, particularly in frequently used methods like permission checks and retrieving channel information.
- We're exploring further balancing of our API infrastructure, potentially using a larger number of smaller Kubernetes pods to distribute the load more effectively and reduce the impact of individual slowdowns.
We're implementing improved caching mechanisms for frequently accessed data, which will reduce the load on our database and improve API response times.Overall, we're approaching these changes cautiously, with a focus on both stability and performance. Each improvement is being carefully tested and rolled out gradually to ensure it doesn't introduce new issues. We're also tweaking our monitoring tools to give us more accurate insights into our system's performance, allowing us to make more informed decisions moving forward.
Our team is committed to resolving these issues and providing a stable, high-performing platform. We'll continue to assess the impact of these changes and make more improvements as needed.
Behind the scenes: what’s been going on for our team
The recent performance issues and slower response times on our customer support team has been a perfect storm of challenges. While all of this was happening, we were in one of our busiest periods, coinciding with summer holidays in the Northern Hemisphere and school vacations.
In addition to the usual seasonal uptick in activity, we also saw a higher volume of people signing up to use Buffer in August and September, an increase in our paying customer base, and a steady release of new features and integrations to continue our work to innovate and modernize Buffer. While these are all very positive indicators for our business, they also placed additional strain on our systems during an already busy time.
Simultaneously, we've been grappling with technical issues stemming from changes happening behind the scenes. These technical challenges have manifested in various ways, affecting different aspects of the Buffer experience.
While it’s no excuse, many of these issues are linked to improvements we're making to Buffer as a whole. We're working on new features and necessary updates to improve our product, but in the process, we've encountered some hurdles that have temporarily impacted our service quality.
We want to assure you that we're taking these challenges seriously and our priority is to improve our customers’ experience. Our team is working to resolve these issues while continuing to improve and expand our service. We need to do better!
What’s next?
The work doesn’t stop with these immediate fixes.
Going forward, we're committed to continuously improving our product experience, with a key company focus on reducing customer friction. Alongside developing new features, our product and infrastructure teams always allocate significant time to evolve and enhance the existing experience and product stability.
In addition, our Engineering team is making several changes to continue to improve Buffer’s performances. Those include:
- Implementing a more comprehensive definition of when an incident is truly “closed.”
- Improving follow-up processes internally with clear responsibilities for incident-follow ups.
- Improving processes for communicating about incidents internally and externally.
- Strengthen collaboration between our development and support teams to manage feature rollouts better and anticipate potential issues.
- Finally, more accountability from our Engineering Leadership team to ensure these processes are followed and prioritizing communication.
We know this has been a challenging time for many of our customers and we’re so grateful for your patience as we improve the quality of our service.
Our team is dedicated to providing you with the best possible experience, and we're keen for you all to have access to product improvements and new features we're bringing to Buffer.
We have a lot more to share on this topic so we’ll be aiming to write more blog posts and share more details about incidents in the future. If there’s anything else you’d like to know about how we manage incidents and our product stability, please reach out or leave a comment below.
Recommended Story For You :
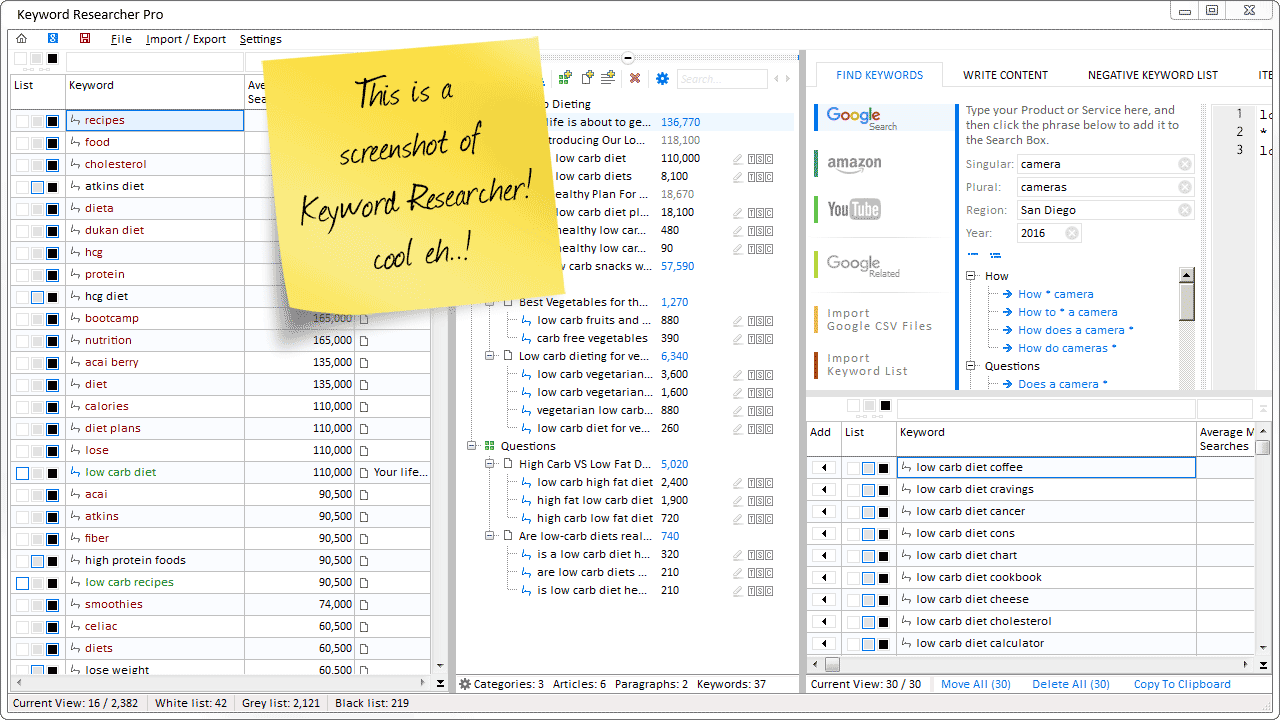
Organize Keywords and Import CSV Files from the Google Keyword Planner
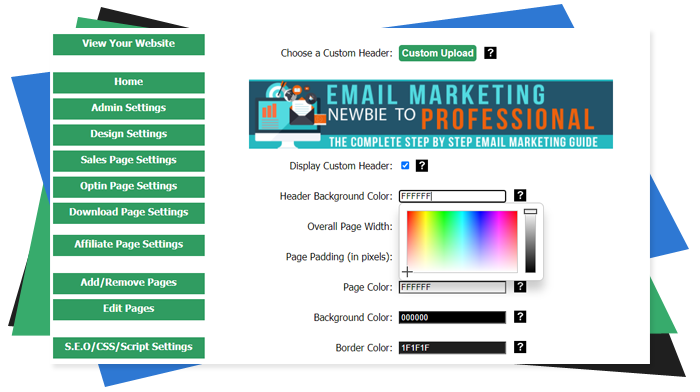
The Most Affordable And Easiest User Friendly Page Builder You Will Ever Use!

Instant WordPress Theme That Matches Your Website
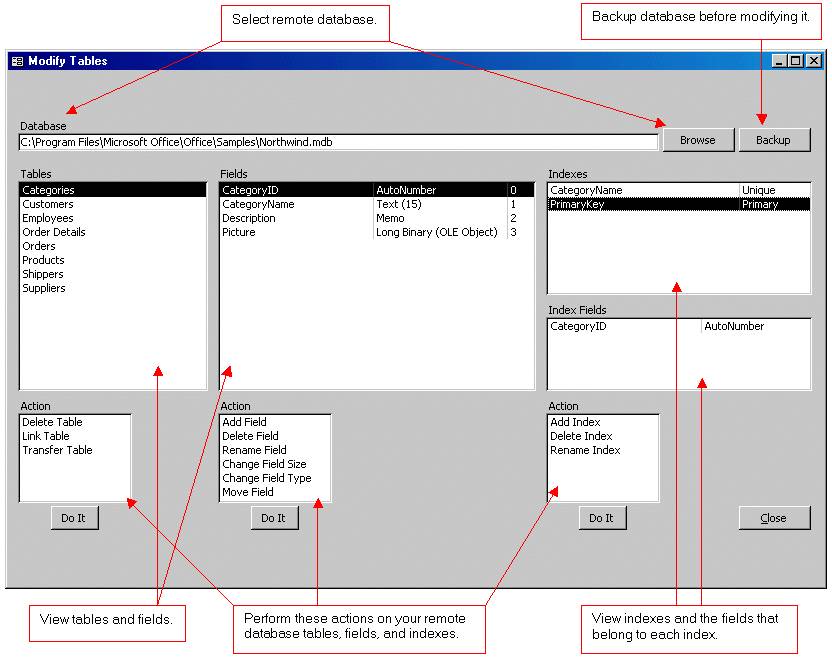
Wizard to Manage Remote Backend MS Access Database Tables Fields and Indexes

If you had an aisle-by-aisle grocery list wouldn't you spend less money on impulse items?
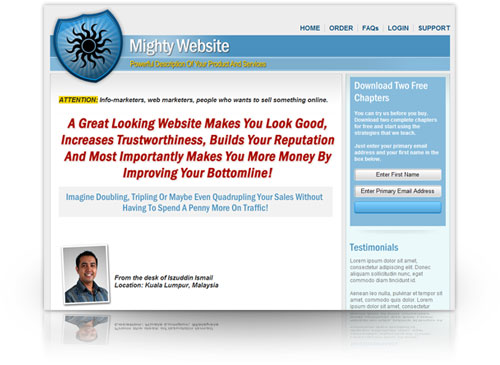
everything you need to create a professional corporate look mini-site is there.

Unlock Your Networking Potential with GNS3Vault
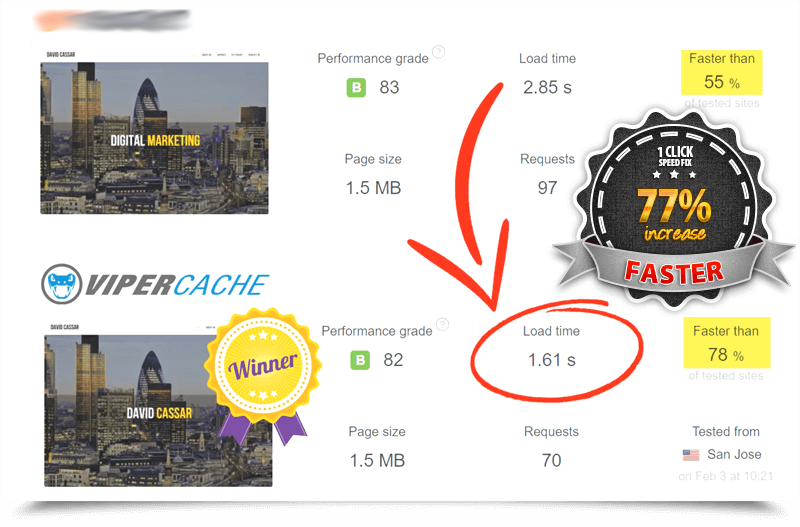
Viper Cache Was 77% Faster Than The Competetion

Understanding Stock Market Shorting eBook
